Всеобщият генетичен код
Генетичният код е специален шифър на наследствената информация с помощта на молекули нуклеинови киселини. Въз основа на това кодирана информация, гени правилно контролират синтеза на протеини и ензими в организма, като по този начин определят метаболизма. От своя страна, структурата на отделните протеини и техните функции се определя от местоположението и състава на аминокиселините - структурните единици на протеиновата молекула.
В средата на миналия век са идентифицирани гени, които са отделни обекти дезоксирибонуклеинова киселина (съкратено като ДНК). Нуклеотидните връзки се образуват в ДНК молекули характерна двойна верига, сглобена под формата на спирала.
Учените са открили връзка между гените и химическата структура на индивидуалните протеини, същността на което се състои в това, че структурното реда на аминокиселини в протеиновите молекули напълно съответства на реда на нуклеотиди в гена. След като установиха тази връзка, учените решиха да дешифрират генетичния код, т.е. установяват законите за съответствие на структурните поредици от нуклеотиди с ДНК и аминокиселини в протеините.
Има само четири типа нуклеотиди:
1) А-аденил;
2) Г-гуанил;
3) Т-тимидил;
4) С-цитидил.
Съставът на протеините включва двадесет вида основни аминокиселини. С дешифрирането на генетичния код възникват трудности, тъй като нуклеотидите са много по-малки от аминокиселините. При решаването на този проблем се предполага, че аминокиселините са кодирани от различни комбинации от три нуклеотида (така наречения кодон или триплет).
Ако преброим всички възможни комбинации, тогава тези триплети ще бъдат 64, т.е. три пъти повече от аминокиселините - получава се излишък от триплети.
Освен това е било необходимо да се обясни точно как се намират триплетите по ген. Така че имаше три основни групи от теории:
1) триплетите следват непрекъснато един след друг, т.е. формират солиден код;
2) триплетите са подредени с редуване на "безсмислени" области, т.е. така наречените "запетаи" и "параграфи" в кода се оформят;
3) триплетите могат да се припокриват, т.е. края на първия триплет може да формира началото на следващия.
Понастоящем се използва главно теорията за последователността на кодовете.
Генетичен код и неговите свойства
1) Триплет код - той се състои от произволни комбинации от три нуклеотида, които образуват кодони.
2) Генетичният код е излишен - това е следствие неговия триплет. Една аминокиселина може да бъде кодирана от няколко кодона, тъй като кодоните, според математическите изчисления, са три пъти по-големи от аминокиселините. Няколко терминиране кодони изпълняват някои функции: някои могат да бъдат "стоп сигнали", които са програмирани производство завършваща амино киселинна верига, докато други могат да представляват започването на кода за четене.
3) Генетичният код е уникален - само една аминокиселина може да съответства на всеки от кодоните.
4) Генетичният код има collinearity, т.е. последователността на нуклеотидите и последователността на аминокиселините ясно съответстват една на друга.
5) Кодът е написан непрекъснато и компактно, в него няма "безсмислени" нуклеотиди. Започва с определен триплет, който се замества от следващия без прекъсване и завършва със стоп кодон.
6) Генетичният код е универсален - гените на всеки организъм кодират информация за протеините по абсолютно същия начин. Това не зависи от степента на сложност на организацията на организма или неговото системно положение.
Съвременната наука предполага, че генетичният код възниква директно, когато новият организъм се роди от костна материя. Случайните промени и процесите на еволюция правят възможни кодовите опции, т.е. аминокиселините могат да бъдат пренаредени във всяка последователност. Защо този вид код оцелее по време на еволюцията, защо е универсалният код и има подобна структура? Колкото повече науката научава за феномена на генетичния код, толкова повече нови загадки възникват.
 Триадичният код и функционалната единица на генетичния код
Триадичният код и функционалната единица на генетичния код Как функционира биосинтезата на протеините?
Как функционира биосинтезата на протеините?- ДНК репликацията е основната фаза
 Нуклеинови киселини: структура и функция. Биологичната роля на нуклеиновите киселини
Нуклеинови киселини: структура и функция. Биологичната роля на нуклеиновите киселини Протеини: Протеинова структура и функция
Протеини: Протеинова структура и функция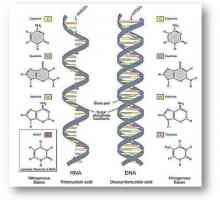 Когато rPHK се синтезира. Рибозомни рибонуклеинови киселини рРНК: характеристика, структура и…
Когато rPHK се синтезира. Рибозомни рибонуклеинови киселини рРНК: характеристика, структура и…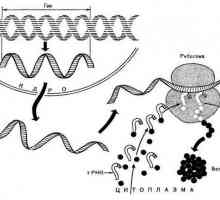 В процеса на синтеза на протеини, какви структури и молекули са пряко включени?
В процеса на синтеза на протеини, какви структури и молекули са пряко включени?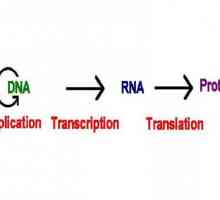 Какво представлява транскрипцията в биологията? Това е стадият на синтез на протеини
Какво представлява транскрипцията в биологията? Това е стадият на синтез на протеини Протеин с кватернерна структура: Характеристики на структурата и функционирането
Протеин с кватернерна структура: Характеристики на структурата и функционирането Какво представлява хроматина: определение, структура и функции
Какво представлява хроматина: определение, структура и функции Мономер на ДНК. Кои мономери образуват ДНК молекула?
Мономер на ДНК. Кои мономери образуват ДНК молекула?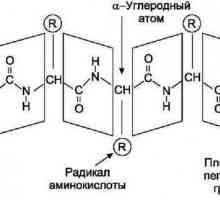 От молекулите на аминокиселинните остатъци на това, което се изгражда?
От молекулите на аминокиселинните остатъци на това, което се изгражда?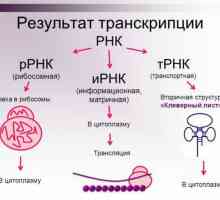 Структура и функция на ДНК и РНК (Таблица)
Структура и функция на ДНК и РНК (Таблица) Макромолекулата е молекула с висока молекулна маса. Конфигурацията на макромолекулата
Макромолекулата е молекула с висока молекулна маса. Конфигурацията на макромолекулата Фибриларен и глобулиран протеин, протеинов мономер, модели на протеинов синтез
Фибриларен и глобулиран протеин, протеинов мономер, модели на протеинов синтез- Нива на структурна организация на протеиновата молекула или структурата на протеина
- ДНК молекула: нива на структурна организация
- Нива на структурната организация на протеиновата молекула: вторичната структура на протеина
- Дезоксирибонуклеинова киселина. Моделът на Крик и Уотсън
 Функции на ДНК и нейната структура
Функции на ДНК и нейната структура Генетична информация: рецесивни и доминантни гени
Генетична информация: рецесивни и доминантни гени